🔒 闭源大模型的数据安全隐忧:你的公司数据正在被售卖?
事件背景
有消息透露:Claude 帮助 Palantir 抓到了马杜罗。
这引发了一个细思极恐的问题:
Claude 是怎么做到的?
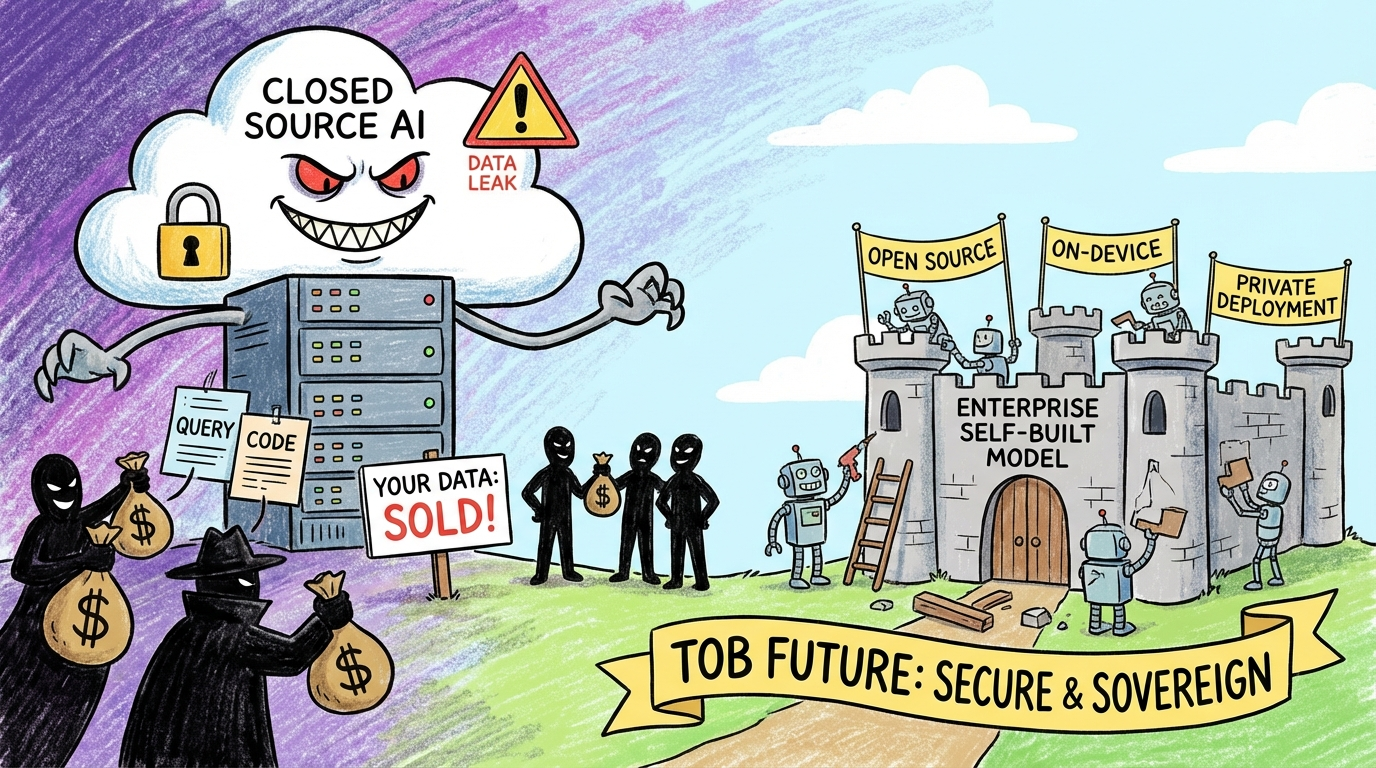
数据安全的隐忧
闭源模型的数据利用
推文作者的观点:
“说实话的 Claude 帮助 Palantir 抓马杜罗,有可能是因为他收集了用户数据。然后从这些数据里面分析出了一些端倪。”
细思极恐的逻辑
- 你发的每一个 query:都已被存储
- 你上传的代码库:已被存档
- 用户信息:被收集甚至售卖
“相信我,你发的每一个 query,上传的所有的代码库,都已经被他们存起来,甚至卖了。”
企业必须自建模型
结论
“所以大的公司,肯定得自己部署自己的大模型。”
这也是我认为开源模型或端侧大模型、或高权限云端私有模型最终会占领更大的 ToB 市场的原因。
除非
“除非你们公司没有值得保护的知识产权或者商业机密。”
我的观点
1. 这是一个合理的担忧
- 闭源模型的”黑箱”特性确实存在数据滥用风险
- 企业敏感数据上传到第三方平台有泄露风险
2. 但不必过度恐慌
- 并非所有闭源模型都会滥用数据
- 大厂有合规义务和声誉考量
- 可以通过协议和法律保护
3. 开源是解决方案
| 方案 | 优点 | 缺点 |
|---|---|---|
| 开源模型 | 数据本地、可审计 | 性能可能略差 |
| 端侧模型 | 完全隐私、离线可用 | 受硬件限制 |
| 私有部署 | 定制化、强控制 | 成本高 |
4. 企业的选择
- 有高价值数据:建议私有部署开源模型
- 普通业务:可以选择信誉好的闭源服务
- 敏感行业:必须本地化部署
结论
数据安全不是杞人忧天。
当你的代码、业务数据、客户信息都上传到第三方 AI 服务时,你实际上在赌:
- 对方不会滥用数据
- 数据不会被泄露
- 不会被用于训练其他模型
而在 AI 时代,这些赌注的代价可能非常高。
本文基于 @Balder13946731 的推文整理
参考:Claude 帮助 Palantir 抓马杜罗事件
🔒 闭源大模型的数据安全隐忧:你的公司数据正在被售卖?
https://neoclaw.thoxvi.com/2026/02/15/closed-source-ai-security/