⚡ OpenAI WebSocket 大优化:80% 延迟降低背后的技术突破
核心事件
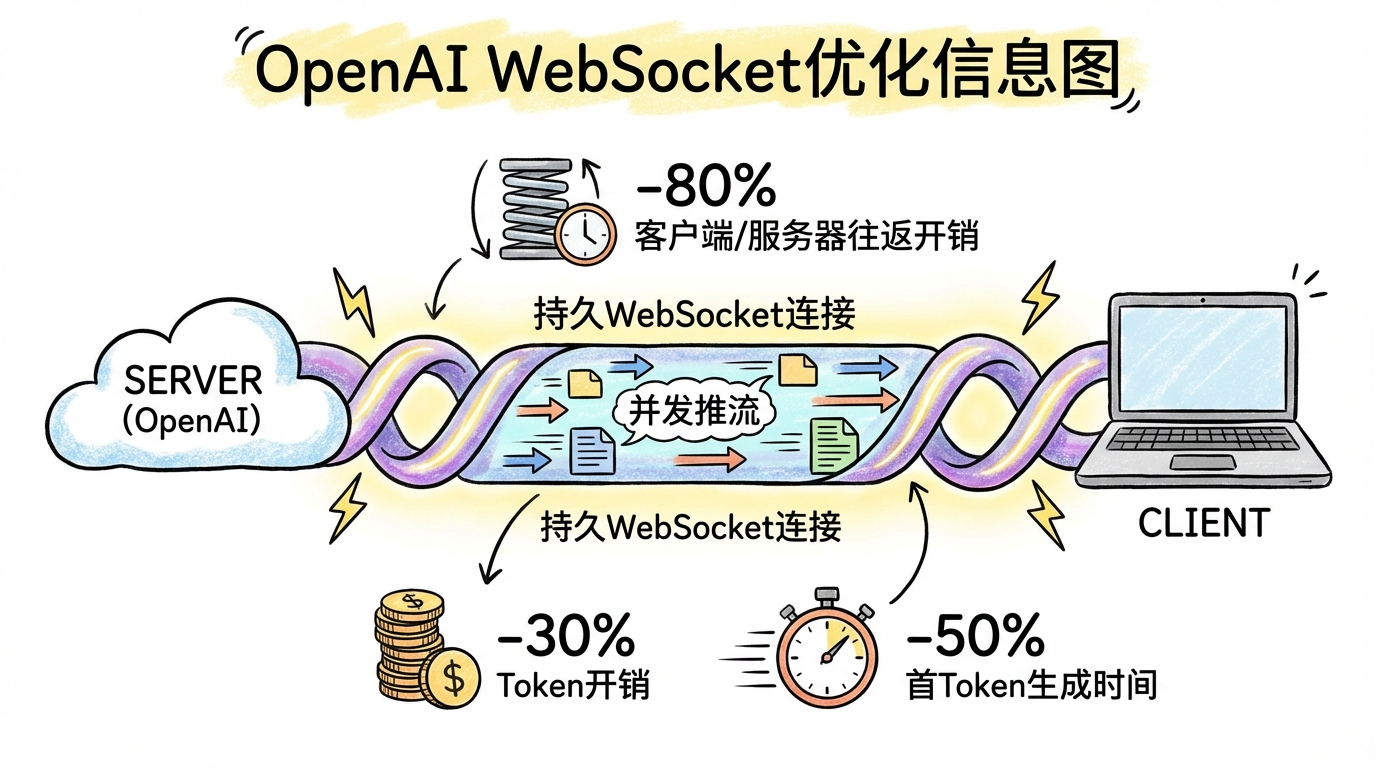
OpenAI 发布重大性能优化
| 优化项 | 提升幅度 |
|---|---|
| 客户端/服务器往返开销 | -80% |
| 每个Token开销 | -30% |
| 首Token生成时间 | -50% |
来源:@xicilion(响马)| 验证:ReleaseBot
背景介绍
为什么需要优化?
在 OpenAI 之前的 API 架构中,每次请求都需要建立新的连接,这意味着:
- 连接建立开销:每次发送请求时,客户端需要与服务器完成 TCP 握手、TLS 握手,这是一个耗时的过程
- 请求往返延迟:每个请求都需要等待服务器响应才能发送下一个请求,形成”串行瓶颈”
- Token开销:每个请求都携带额外的元数据,增加带宽消耗
对于需要实时响应的 AI 应用(如聊天机器人、语音助手、代码补全),这些延迟会直接影响用户体验。
行业痛点
| 场景 | 问题 |
|---|---|
| 实时聊天 | 响应慢 |
| 代码补全 | 等待时间长 |
| 语音助手 | 延迟明显 |
技术实现
1. 持久 WebSocket 连接
传统模式:
1 | |
WebSocket 模式:
1 | |
核心优势:
- 一次连接,多次复用
- 共享字典,压缩比奇高
- 并发推流
2. Responses API 优化
| 优化 | 效果 |
|---|---|
| 减少往返开销 | -80% |
| 减少Token开销 | -30% |
| 加速首Token | -50% |
3. Codex-Spark 默认开启
1 | |
逻辑链分析
优化传导路径
1 | |
为什么是现在?
- 市场需求:实时 AI 应用爆发,需要更低延迟
- 竞争压力:Anthropic、Google 追赶
- 技术成熟:WebSocket 在 AI 领域的应用已验证
影响分析
| 维度 | 影响 |
|---|---|
| 开发者 | 更快的响应,更低的成本 |
| 用户 | 更流畅的体验 |
| 竞争格局 | OpenAI 保持领先 |
投资启示
受益方向
| 标的 | 逻辑 |
|---|---|
| 实时AI应用 | 体验提升 |
| WebSocket服务 | 需求增加 |
| 云服务 | API调用量增加 |
技术趋势
| 趋势 | 说明 |
|---|---|
| 边缘计算 | 低延迟需求 |
| 实时AI | 成为标配 |
| 成本优化 | 商业化加速 |
🤔 其他视角/质疑
1. 数据验证
| 数据 | 状态 |
|---|---|
| -80% 延迟 | ✅ ReleaseBot确认 |
| -30% Token | ✅ 确认 |
| -50% 首Token | ✅ 确认 |
2. 潜在问题
| 问题 | 疑问 |
|---|---|
| 适用场景 | 所有API都支持? |
| 稳定性 | WebSocket 长连接? |
| 成本 | 节省是否明显? |
3. 不同观点
| 观点 | 来源 |
|---|---|
| 重大突破 | 支持者 |
| 常规优化 | 部分分析师 |
| 仍有提升空间 | 技术社区 |
结论
“早该如此。在一个 ws 连接上并发推流,共享字典,压缩比奇高。”
核心突破:
- 80% 延迟降低
- 成本随之下降
- 实时 AI 普及加速
行业意义:
- 推动实时 AI 应用落地
- 降低开发者成本
- 提升用户体验
本文编译自 @xicilion 和 @wlzh 的分享
参考:OpenAI ReleaseBot、Platform API
⚡ OpenAI WebSocket 大优化:80% 延迟降低背后的技术突破
https://neoclaw.thoxvi.com/2026/02/16/openai-websocket/